JCuda - ニューラルネットの実装
ニューラルネットを JCuda 版に書き換えます。
全てを CUDA 上で行う方法と、内側のループあるいは並列計算のみ CUDA で行う方法の2つに大別されますが、今回は対応が分かりやすい後者の方法を選びました。
ポイントは2つあります。
- 出力ノード別に並列化する
- BATCHSIZEに展開して並列化する
出力ノード別の並列化でも5割位速度向上しますが、CUDA の能力の数%しか利用しません。
やはり BATCHSIZE についても並列化し、全ての CUDA コアを使い切ります。
プログラムはやや複雑化しますが、こうすると10倍以上の高速化が可能となります。
さて、ニューラルネットのプログラムは以下のソースファイルから構成されるのでした。
- SimpleNet.java
- NeruralNet.java
- ILoader.java
- ImageLabelSet.java
- MNIST.java
- ILossFunction.java
- QuadLossFunction
- TestMnist.java
JCuda の初期化メソッド
JCuda 版ではデバイスメモリで実行される関数を集めたソースファイル JCudaNNKernel.cu を用意します。
損失関数はこのソース内で処理されるため、ILossFunction, QuadLossFunction は削除します。
一方、JCuda の初期化をまとめて行うため、NNUtil.java を導入し、static 関数を定義します。
public class NNUtil {
public static Map<String, CUfunction> initJCuda(String cuFileName) {
// 例外処理を有効にする
JCudaDriver.setExceptionsEnabled(true);
// cu ファイルから ptx ファイルを(必要なら)コンパイルしてロー>ド
String ptxFileName = preparePtxFile(cuFileName);
// CUDA ドライバーを初期化し、最初のデバイスに対するコンテキストを作成する
cuInit(0);
CUcontext pctx = new CUcontext();
CUdevice dev = new CUdevice();
cuDeviceGet(dev, 0);
cuCtxCreate(pctx, 0, dev);
// PTX ファイルを読み込む
CUmodule module = new CUmodule();
cuModuleLoad(module, ptxFileName);
// カーネル関数を展開する
Map<String, CUfunction> fMapper = new ConcurrentHashMap<String, CUfunction>();
createMapper(fMapper, module);
return fMapper;
}
}
fMapper は関数名からエントリポイントを返す辞書型変数となります。
MNIST.java へのデバイスメモリの追加
MNIST.java を、ホストメモリ、デバイスメモリの両方を管理するように書き換えます。
devMem を devMemArray ポインタの配列へのポインタ、devMemArray を2次元配列のx要素へのポインタとします。
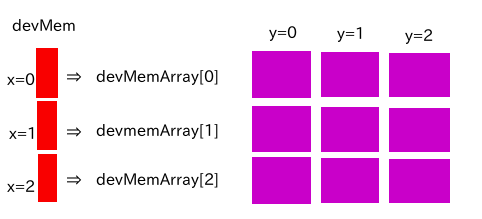 このとき、2次元配列の要素 x, y へのアクセスは devMem[x][y] で表されます。
このとき、2次元配列の要素 x, y へのアクセスは devMem[x][y] で表されます。
devMem[x] で対象となる devMemArray を選択し、この devMemArray を使って devMemArar[y] を選択するイメージとなります。
インスタンスを作成した後に画像データを指定できるようにするため、setContentDev() メソッドを用意しました。クラスによってシグニチャが多少異なりますが、一連の操作の前に必ずこのメソッドを呼ぶ必要があります。
今回は MNISTImage, MNISTLabel 内でデバイスメモリを管理するようにしました。
ILoad にメモリ管理用の3つのメソッドを追加します。
-
CUdeviceptr getContentDev(int index)
指定した index に対応する devMemArray へのポインタを返します。
-
CUdeviceptr getContentDev()
devMem へのポインタを返します。
-
void setContentDev()
デバイスメモリにホストメモリの内容を転送する。
SimpleNet へのデバイスメモリの追加
パーセプトロンへのデバイスメモリの追加
パーセプトロンにデバイスメモリ管理を追加し、結果をホストメモリではなく、デバイスメモリに持つようにします。
そのために devOutz, devOutzArray, devTmpz, devTmpzArray を定義します。
これらはパーセプトロンの出力値、線形和の結果保持に使用されます。
batchsize に関して並列化するため、入力、出力ともに2次元配列として定義されることに注意します。
線形和や非線形関数は batchsize 方向の添字によらない値となるため、3重ポインタは必要ないことにも注意してください。
最終段は softmax 関数となるため、出力値が全て揃わないと計算できません。
そのため、__syncthreads() で全てのスレッドの計算終了を待ってから非線形関数の計算を行っています。
shared memory を使うことも検討しましたが、64k bytes の制限に収まらなかったので、今回は採用を見送りました。
shared memory を使うともっと速くなる可能性があります。
forward メソッドを2次元のデバイスメモリを入力とし、2次元のデバイスメモリを出力とするメソッドに書き換えます。出力段は常に devOutz が返されます。
CUdeviceptr forward(CUdeviceptr in) {
int fmt = format2no(format);
Pointer kp = Pointer.to(
Pointer.to(devOutz), Pointer.to(devTmpz),
Pointer.to(devW), Pointer.to(devB), Pointer.to(in),
Pointer.to(new int[]{inn}), Pointer.to(new int[]{outn}),
Pointer.to(new int[]{fmt}), Pointer.to(new int[]{batchsize})
);
cuLaunchKernel(fMapper.get("calc_forward"),
calcBlock2D(outn), calcBlock2D(batchsize), 1,
NTHREAD2, NTHREAD2, 1,
0, null,
kp, null
);
cuCtxSynchronize();
return devOutz;
}
CUDA 側のプログラムは以下のようになります。
extern "C" __global__ void
calc_forward(float **out, float **tmp, float **w, float *b, float **in, int inn, int outn, int fmt, int batchsize) {
const int o = blockDim.x * blockIdx.x + threadIdx.x;
const int s = blockDim.y * blockIdx.y + threadIdx.y;
// 線形和の計算
if (o < outn && s < batchsize) {
float t = 0.0f;
for (int i = 0; i < inn; ++i) {
t += in[s][i] * w[i][o];
}
t += b[o];
tmp[s][o] = t;
}
__syncthreads();
// 非線型関数の出力
if (o < outn && s < batchsize) {
if (fmt == 1) {
// softmax 関数
float xmax = calc_xmax(tmp[s], outn);
float divisor = calc_div(tmp[s], outn, xmax);
outz[s][o] = calc_softmax(tmp[s], xmax, divisor, o);
} else {
// sigmoid 関数
outz[s][o] = sigmoid(tmp[z][o]);
}
}
}
逆誤差散乱法記述の修正
誤差逆伝搬法による係数の推定は、原則的には batchsize 毎に行います。
ただし、w については損失関数の評価時に batchsize 方向に加算してしまうため、outn * batchsize の2次元配列として実現します。
つまり、batchsize 方向の加算を行った結果を保持するようにします。
calc_deriv_b は bMostouter が true の時と false の時で引数が異なります。
- true の時
引数並びは calc_b_deriv(devDB, devBhot, devSamples, true) となります。
devSamples は連番を乱数に変換するための、batchsize 個の要素を持つ int 配列です。
samples は host 側で作成し、予めデバイスメモリ devSamples にコピーしておく必要があります。
- false の時
引数並びは calc_b_deriv(devDB, devW, devOutz, devDB2, false) となります。
devDB2 は1つ下の層の devDB を入力します。
devDW の計算は JCuda 版でも同様ですが、入力が2次元配列の CUdeviceptr に変更になることと、batchsize 方向の加算があることに注意します。
Java での記述は以下のようになります。
public void calc_deriv_w(CUdeviceptr devDW,
CUdeviceptr in, int xsize, CUdeviceptr delta, int ysize) {
Pointer kp = Pointer.to(Pointer.to(devDW),
Pointer.to(in), Pointer.to(new int[]{xsize}),
Pointer.to(delta), Pointer.to(new int[]{ysize}),
Pointer.to(new int[]{batchsize})
);
cuLaunchKernel(fMapper.get("calc_deriv_w_kernel"),
calcBlock2D(xsize), calcBlock2D(ysize), 1,
NTHREAD2, NTHREAD2, 1,
0, null,
kp, null);
cuCtxSynchronize();
}
JCudaNNKernel.cu での記述は以下のようになります。
// 損失関数の w 方向の微分
extern "C"
__global__ void calc_deriv_w_kernel(float **dw, float **in, int xsize, float **d
b,
int ysize, int bs) {
const int x = blockDim.x * blockIdx.x + threadIdx.x;
const int y = blockDim.y * blockIdx.y + threadIdx.y;
if (x < xsize && y < ysize) {
float d = 0.0f;
// batchsize 方向に加算してしまう
for (int z = 0; z < bs; ++z) {
d += in[z][x] * db[z][y];
}
dw[x][y] = d;
}
}
確率的最急降下法の適用
最後に確率的最急降下法を適用するときは batchsize 方向に加算します。dw についてはすでに加算されているため、db について加算します。
// b に関する学習
extern "C" __global__ void
learn_1d(float *bout, floar **deriv. float lrate, int size, int nsample, int bs) {
const int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < size) {
for (int s = 0; s < bs; ++s) {
bout[i] -= lrate * deriv[s][i] / nsample;
}
}
}
bathsize が 2 のベキ乗ならば reduce 操作によってより効率的な加算が可能ですが、一般的な値を使用することを考慮して、for ループにしています。
デバイスメモリの解放
デバイスメモリは Java 標準でない cuMemAlloc() で確保したため、オブジェクトがガーベージコレクションによって破棄されたタイミングでデバイスメモリも破棄するようにする必要があります。
具体的にはデバイスメモリを確保したクラスに public void finalize() を作成し、後処理を記述していきます。
SimpleNet の場合の記述は以下のようになります。
public void finalize() {
IntStream.range(0, inn).forEach(i->{
cuMemFree(devWArray[i]);
});
cuMemFree(devW);
cuMemFree(devB);
IntStream.range(0, batchsize).forEach(i->{
cuMemFree(devOutz2D[i]);
});
cuMemFree(devOutz);
IntStream.range(0, batchsize).forEach(i->{
cuMemFree(devTmpz2D[i]);
});
cuMemFree(devTmpz);
}
Copyright (c) 2017-2019 by TeqStock.tokyo